GAIA: A Fine-grained Multimedia Knowledge Extraction System
Manling Li*, Alireza Zareian*, Ying Lin, Xiaoman Pan, Spencer Whitehead, Brian Chen, Bo Wu, Heng Ji, Shih-Fu Chang, Clare R. Voss, Dan Napierski, Marjorie Freedman (* equal contribution)
Contact: manling2@illinois.edu, az2407@columbia.edu, hengji@illinois.edu, sc250@columbia.edu
About
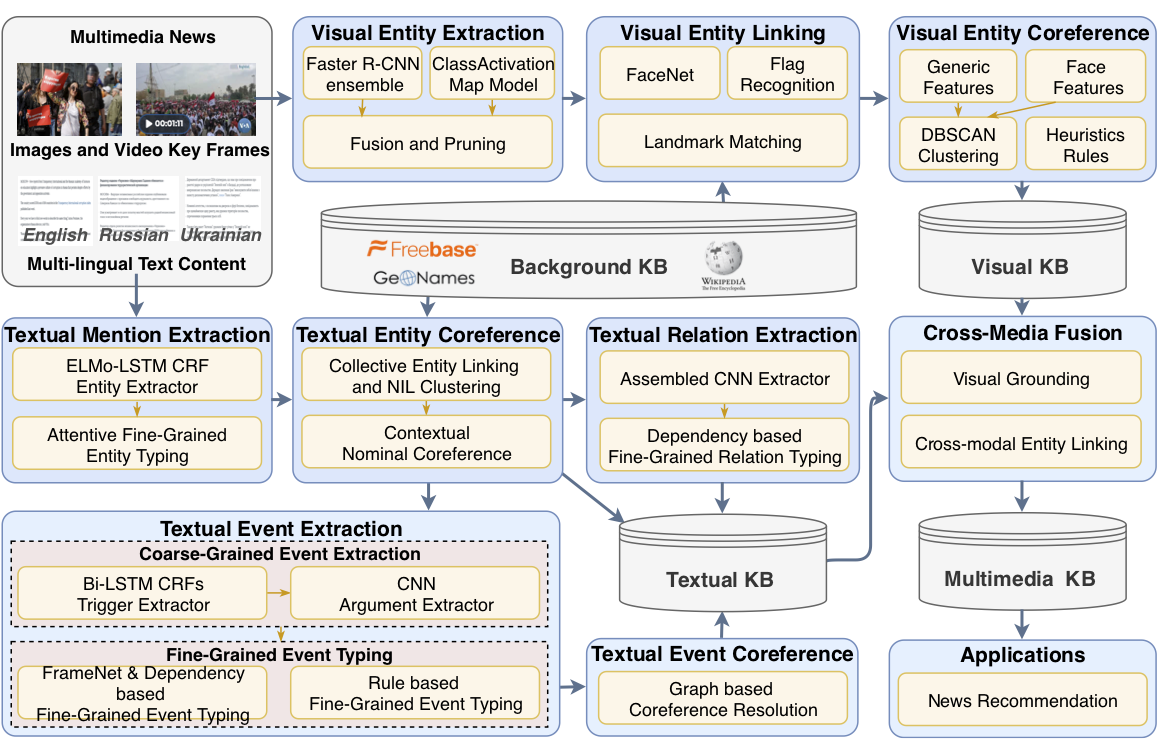
We present a comprehensive, open source multimedia knowledge extraction system GAIA that takes a massive stream of unstructured, heterogeneous multimedia data from various sources and languages as input, and creates a coherent, structured knowledge base, indexing entities, relations, and events, following a rich, fine-grained ontology.
Intellectual Objective and Broad Impact
Our goal in developing multimedia multi-lingual knowledge extraction systems is to advance the state of the art and enhance the field's ability to harness rich information from multiple sources and modalities. We believe that to make real progress in NLP and CV, we should not focus only on datasets, but to also ground our work in real-world applications. The application we focus on is navigating news, and the examples shown here and in the paper demonstrate the potential use in news understanding and recommendation in the international news domain.
We are particularly excited about the potential use of the technologies in applications of broad societal impact, such as emergency response and scientific knowledge discovery. In a recent collaborative project, we have applied our multimedia knowledge extraction technology to extract and discover information from the text and figures in a large collection of COVID-19 related papers to assist scientists and clinical experts in the process of discovery and development of therapeutic solutions to meet the ongoing pandemic challenges. In another project in collaboration with Dr. Rahel Jhirad, we have also explored the use of the multimedia knowledge extraction methods in improving the process of local news production.
The knowledge elements extracted in this project are limited to entities mentioned in multimodal documents (text or images) from the public newsfeed only. We appreciate the important findings and discussion about ethics shared in the community (e.g., [Raji et al., 2020 AAAI/ACM Conference on AI, Ethics, and Society]; [Buolamwini and Gebru, 2019 Conference on Fairness, Accountability and Transparency]; [Nkonde, Harvard Kennedy School Journal of African American Policy 2019-2020]) and fully support including ethics as a fundamental topic in research and development in this emerging field of multimodal knowledge extraction.
Tasks
- Multimedia Entity Extraction aims to identify entity mentions in text and classify them into pre-defined entity types. A mention can be a name, nominal, or pronoun, or an image bounding box.
- Multimedia Relation Extraction is the task of assigning a relation type to a pair of entity mentions.
- Multimedia Event Extraction entails identifying event triggers (the words or phrases that most clearly express event occurrences) and their arguments (the words or phrases for participants in those events) in unstructured texts and classifying these phrases, respectively, for their types and roles. An argument can be an entity, time expression, or value (e.g., money, job-title, crime).
Download
GitHub DockerHub EventRecommendation Demo
| Component | Description | Link |
|---|---|---|
| Text-IE | - Support entity extraction of 187 fine-grained types (Ontology) - Support relation extraction of 61 fine-grained types (Ontology) - Support event extraction of 144 fine-grained types (Ontology) - Support entity linking to Freebase and GeoNames - Support entity coreference - Support event coreference |
Download |
| Object Detection | - Detect visual entities (Ontology) | Download |
| Recognition of Public Figures | - Detect visual named entities of public figures, and link them to Wikipedia (Ontology) | Download |
| Crossmedia Fusion | - Ground visual entities to text entiteis | Download |
Acknowledgement
This research is based upon work supported in part by U.S. DARPA AIDA Program No. FA8750-18-2-0014 and KAIROS Program No. FA8750-19-2-1004. The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies, either expressed or implied, of DARPA, or the U.S. Government. The U.S. Government is authorized to reproduce and distribute reprints for governmental purposes notwithstanding any copyright annotation therein.
References
Manling Li, Alireza Zareian, Ying Lin, Xiaoman Pan, Spencer Whitehead, Brian Chen, Bo Wu, Heng Ji, Shih-Fu Chang, Clare R. Voss, Dan Napierski, Marjorie Freedman. 2020. GAIA: A Fine-grained Multimedia Knowledge Extraction System. Proceedings of The 58th Annual Meeting of the Association for Computational Linguistics Demo Track (Best Demo Paper Award).
Wang, Qingyun, Manling Li, Xuan Wang, Nikolaus Parulian, Guangxing Han, Jiawei Ma, Jingxuan Tu et al. "COVID-19 Literature Knowledge Graph Construction and Drug Repurposing Report Generation." arXiv preprint arXiv:2007.00576 (2020).